

The Unfuddle Blog: Maintenance
-
UI Updates and The New Board in Unfuddle STACK
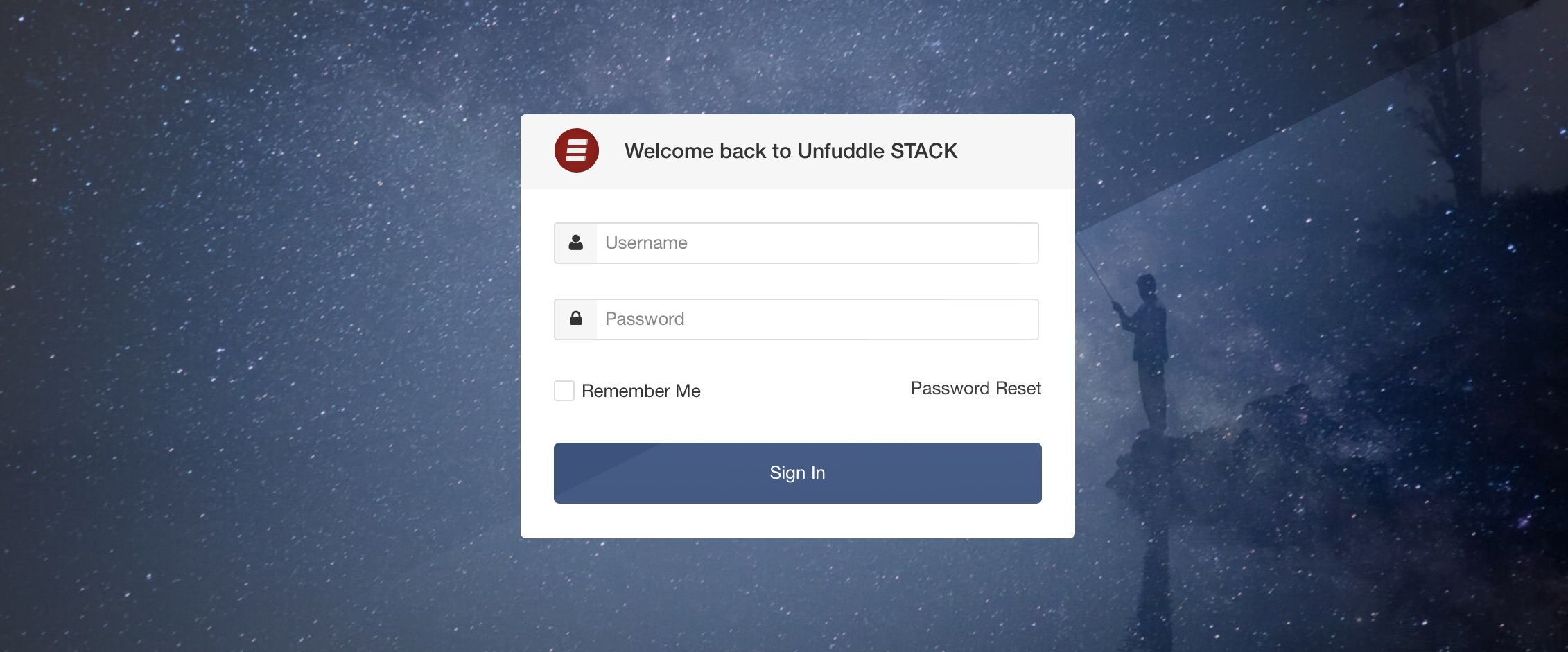
You may recall that, in response to our survey earlier this year, we committed to some pretty significant updates to Unfuddle STACK. We started by implementing sweeping performance improvements. And now we are doubling down on our commitments by releasing a very exciting, and very visible update to the user interface.
-
Two-Factor Authentication Updates for Unfuddle STACK

We have recently deployed an update that will allow you to use your favourite Authenticator to sign in to your Unfuddle STACK account!
Here are some of the many Authenticators that are now compatible with our 2FA system:
-
Last month a vulnerability was discovered for SSLv3 by the name of POODLE (Padding Oracle On Downgraded Legacy Encryption) allowing man-in-the-middle attackers to view encrypted information in plain text. With that said, SSLv3 is no longer secure and we have removed this protocol from our servers in favor of TLS.
-
Two-Factor Authentication in Unfuddle
Today we're happy to announce that we've enabled two-factor authentication for all web access to Unfuddle accounts!
Two-factor authentication adds a strong layer of security to accounts by requiring not just a username and password, but also an additional code which is tied to a device you have in your possession, typically a mobile device, such as a smartphone. This means that, once enabled, in order to sign in to you will need to provide both your username and password AND have your device with you in your possession.
-
On Monday, April 7th, a serious vulnerability in the OpenSSL cryptographic software library, known as Heartbleed, was publicly disclosed. OpenSSL is a very popular library used for providing secure and private communication for services such as websites, email, virtual private networks and more. This includes most communication with Unfuddle and similar services.
-
Starting at about 7:45am PDT today, a number of our customers began reporting connectivity issues with their Unfuddle accounts. The connectivity issues seem to only be affecting a small subset of Unfuddle accounts.
According to Amazon, the problem is currently global to Amazon EC2 and has been isolated to a “problematic transit route leading into the US-EAST-1 region”. Amazon is currently working with major service providers to reroute traffic and resolve this issues.
For more information about the progress of resolving the issue, please stay tuned by visiting: https://status.aws.amazon.com
We apologize for any inconvenience this may have caused you or your team.
UPDATE (3:02pm PDT):
Amazon indicates that they believe that all identified connectivity issues have been resolved. Please let us know at Unfuddle support if you continue to have any trouble accessing your Unfuddle account.
-
Earlier today, May 27, at approximately 10:15EST, one of the Unfuddle servers experienced a hardware failure with its attached storage (an Amazon EBS volume).
Immediately upon failure, we contacted the Amazon support team and began the process of diagnosing the problem. At approximately 20:00EST, the hardware failure was remedied, the volume was restored and all Unfuddle accounts on that server were available as normal.
Why did we take so long to respond? Unfuddle keeps hourly snapshots of all customer data, so it would have been possible from the very moment of the outage to revert to a saved snapshot. However, doing so would have caused everyone on the server to lose approximately one hour of activity on their account – a situation we clearly wanted to avoid. As we worked with Amazon throughout the day, it was looking probable that the data on the volume would be recoverable, avoiding any data loss. Unfortunately, only in the early evening was it actually guaranteed to us by Amazon the volume was intact and had been recovered successfully.
As many of you know, we have been with Amazon EC2 since the beginning of this year and this is the first significant outage we have experienced since then. Our current data partitioning and snapshotting scheme has been excellent at mitigating risk for our customers. Even today, only about 7% of all Unfuddle accounts were affected. However, we do not consider this outage to be acceptable, and in hindsight we should have probably not waited for the volume to be rebuilt, but rather restored directly from the last viable snapshot.
This morning’s events have given us some very practical ideas as to how we can even further improve upon our snapshotting strategy so that this kind of hardware failure is even less likely to affect our customers in the future. We are already working on implementing these changes.
We apologize for the disruption that this outage has caused you and your teams. As a software development team ourselves, we truly understand the kind of problems that this has caused.
-
As many of you may have noticed, we have been experiencing some performance and connectivity issues since about 2pm EST. The issue is now remedied, however, I wanted to take a few moments to update you as to the cause of the problem.
Unfuddle has been growing rapidly. Yesterday afternoon, in response a recurring problem with our load balancer, we made the decision to swap it out for a new one that would provide a more robust and responsive experience. While the transplant appeared to have gone well, there were a number of problems that only began to surface earlier this morning.
As of an hour ago, we have swapped yet a different load balancer into place and Unfuddle is now back up and running.
I apologize for this inconvenience.
-
Earlier today, we began experiencing some strange issues with our email server. Many of our customers began reporting that they were not receiving email notifications, password reminders and the like. Upon further investigation, we have learned that this problem has been intermittent, and has been happening for about the past week.
As soon as we discovered the problem, we immediately took measures to remedy it. We have just finished installing a new mail server. With this upgrade, everyone should once again be receiving email.
Please note that any invites you may have sent over the past week may not have been received by the intended recipients. You can either manually notify these people or re-invite them into your account.
We apologize for any inconvenience this may have caused. If you have any questions regarding this issue, please do not hesitate to contact us.
-
At approximately 8:00pm EST on November 12, our primary data center in Dallas, TX experienced a serious power failure due to a transformer explosion. Upon switching to generator power, the facility was unable to start the necessary cooling systems. As such, our servers were manually taken down to prevent overheating.
While the situation has now been remedied, we are already working hard to establish processes such that this kind of downtime will not happen again.
We apologize deeply for any inconvenience this may have caused our customers.
-
Starting at approximately 9:06am EST, Unfuddle began slowing down significantly for all Unfuddle customers. Shortly thereafter, the site became completely unresponsive. We have been working diligently to resolve the issue and the site is now back up and running.
Please note that no customer data was at risk during this outage as it was caused by extensive load on our servers.
We apologize for any inconvenience this may have caused. We are already investigating ways to make sure that this does not happen again.
The Unfuddle Team
-
Growing Pains
At approximately 1:00am EST on Sunday, September 16th 2007, Unfuddle will be unavailable for approximately 30 minutes for a previously unscheduled maintenance window.
During this downtime, we will be addressing some of the performance issues that many of our most active customers have noted over the past two weeks. In direct response, we will be optimizing our Rackspace server infrastructure as well as deploying a number of code optimizations.
We apologize for any inconvenience that either the performance issues or this maintenance window may have caused. If you have any questions, please do not hesitate to contact us.