

The Unfuddle Blog
-
Many of you have asked for the ability to create and set custom fields for your tickets in Unfuddle. We are happy to announce that this is now possible!
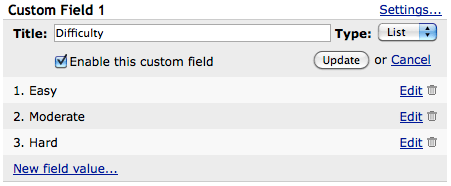
Every Unfuddle project now provides three totally customizable ticket fields. Each field can be assigned a custom title and any number of values. These values can come from a list, pre-specified by an account administrator, or they can be arbitrarily specified during the creation or editing of a ticket.
Smarter Ticket Interface
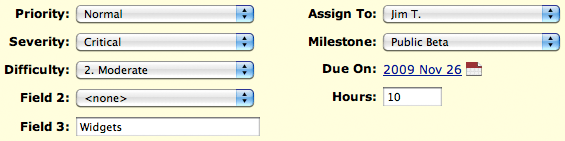
Each custom ticket field can be marked as active or inactive indicating whether or not it should be shown in the interface. Along with this, we have also hidden any unused fields (Severity, Component, and Version) from the ticket interface to remove unnecessary clutter. This means, for example, that if you have no Components defined for a project, the “Components” field will not be displayed for tickets in that project.
Unfuddle API Integration
As with all other aspects of your Unfuddle account, custom ticket fields can be modified via the Unfuddle API allowing for even more flexible integration with outside tools.
As always, thanks to everyone who has taken the time to share comments and feedback. We are excited to be working on a number of additional enhancements and additions for release in the near future.
-
For those of you who have time tracking enabled on your projects, we have just rolled out a number of changes to time tracking.
Powerful Commit Messages
We have added a few time tracking related actions to our Powerful Commit Messages. It is now possible to specify how many hours you have spent on a ticket using the following syntax:
> svn commit -m 'spent 5.5 hours on #498' > svn commit -m 'resolved #47 spending 2:45 on #47' > git commit -am 'worked 3 hours on #99'The keywords that will trigger the creation of a time entry are: spend, spent, spending, invest, invested, investing, work, worked, working.
Please note that the ticket number must always be specified in association with one of the above keywords and they must always be separated by either the word "on" or "hours on" (i.e. "5:30 on #43" or "5.5 hours on #43").
Time Entry on Ticket Resolution
When resolving a ticket, it is often necessary to create a time entry representing the work you put in to close the ticket. Previously, this was a 2-step process. Now, you can simply specify the amount of time spent resolving a ticket right from the ticket resolution form.
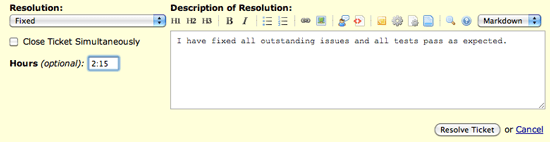
Additionally, as you may have noticed from above, it is now possible to use a more natural ":" separated notation everywhere you enter hours. For instance, instead of having to write 10 minutes as "0.1666", it is now possible to simply write "0:10".
-
Starting at about 7:45am PDT today, a number of our customers began reporting connectivity issues with their Unfuddle accounts. The connectivity issues seem to only be affecting a small subset of Unfuddle accounts.
According to Amazon, the problem is currently global to Amazon EC2 and has been isolated to a “problematic transit route leading into the US-EAST-1 region”. Amazon is currently working with major service providers to reroute traffic and resolve this issues.
For more information about the progress of resolving the issue, please stay tuned by visiting: https://status.aws.amazon.com
We apologize for any inconvenience this may have caused you or your team.
UPDATE (3:02pm PDT):
Amazon indicates that they believe that all identified connectivity issues have been resolved. Please let us know at Unfuddle support if you continue to have any trouble accessing your Unfuddle account.
-
Unfuddle Screenshots with Freshlog
I don’t know about you, but when I create a ticket in Unfuddle, I often want to attach a screenshot illustrating the problem. We recently reviewed an application developed by one of our customers that makes the process of creating a ticket with a screenshot much easier.
Enter Freshlog
Freshlog is a Mac OS application that makes it very simple to take a screenshot, crop it, annotate it and upload it to a new or existing ticket within your Unfuddle account. Launch the app, enter your Unfuddle credentials and then ticket creation with attachments is only a keyboard shortcut away!
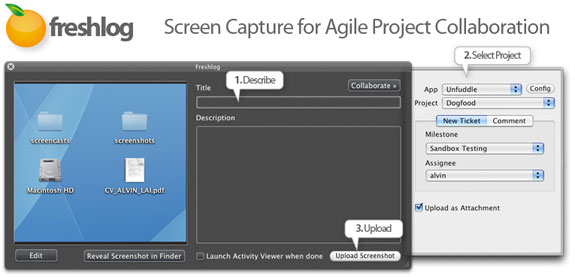
For more information on the app, visit https://freshlog.com.
-
Today, in response to your feedback, we are releasing an update that provides a number of changes to editing formatted fields in Unfuddle.
Editor Toolbars
Let’s be honest, Markdown and Textile can be a bit daunting for non-technical users. When editing a formatted field (such as ticket description), you will now see a custom toolbar depending on your markup of choice. This toolbar contains buttons for some of the most common formatting tasks (bold, italic, strikeout, etc) making the specifics of your markup language much easier to remember. The toolbar also includes buttons for inserting links to Unfuddle tickets, changesets, repository source code, etc.

Per Field Markup
Every formatted field now independently stores the markup language in which it was authored. This means that you can also change the markup used for any text field at the time of edit. This has some interesting implications. For instance, if you previously authored all of your Unfuddle content using Textile, but decide to switch to Markdown, all of your old content will still render correctly.
We have also made it possible for each person to individually specify their desired markup to be used when authoring new content from the Personal Settings page. Now, your Textile fanatic can finally have his way. However, you should note that it is possible to restrict which markup languages are available to your users from the Account Settings page. In this way, you can prevent any new material from being authored in a markup that you find undesirable.
Text Preview
Many of you have asked for the ability to preview a ticket, message, or notebook page before posting. Well, now you can! Simply click the appropriate button in the toolbar and you will be shown a nearly instant preview of your formatted text.

Please enjoy the new editing ease and be sure to let us know what you think!
-
Recovery Strategy Improvements
As we intimated in our previous post, the outage we experienced offered us an opportunity to evaluate our disaster recovery plan under pressure. While I am glad to say that no data was lost in the hardware failure, our team was convinced that there was definite room for improvement. After bringing the affected customers back online, we immediately began work on evaluating alternate systems and processes that would have shortened this weekâs downtime dramatically.
We are now taking snapshots of all customer data at 5 minute intervals. This provides us with two distinct advantages:
- As many of you may know, Amazon EBS volumes are already redundant, a hardware failure on an Amazon EBS volume usually means a drastic reduction in speed, not a complete failure. This was the case on Wednesday. In the case of reduced performance, we can take down the affected server, take a final snapshot capturing any disk activity since the last 5 minute snapshot. This should go fairly quickly even on a volume experiencing problems.
- In the case of the catastrophic failure on an EBS volume, we can very quickly restore customer data from the last snapshot losing only 5 minutes of data.
If we had been using the 5 minute snapshot scenario before Wednesday, the downtime would have been lessened to approximately 30 minutes – the amount of time for one of us to manually snapshot the affected volume, create a new volume from that snapshot and reattach it.
I want to thank all of you for your support and suggestions since this outage. Know that we are committed to the integrity and availability of your data and we will continue to evolve our systems and processes to make Unfuddle even more solid.
-
Earlier today, May 27, at approximately 10:15EST, one of the Unfuddle servers experienced a hardware failure with its attached storage (an Amazon EBS volume).
Immediately upon failure, we contacted the Amazon support team and began the process of diagnosing the problem. At approximately 20:00EST, the hardware failure was remedied, the volume was restored and all Unfuddle accounts on that server were available as normal.
Why did we take so long to respond? Unfuddle keeps hourly snapshots of all customer data, so it would have been possible from the very moment of the outage to revert to a saved snapshot. However, doing so would have caused everyone on the server to lose approximately one hour of activity on their account – a situation we clearly wanted to avoid. As we worked with Amazon throughout the day, it was looking probable that the data on the volume would be recoverable, avoiding any data loss. Unfortunately, only in the early evening was it actually guaranteed to us by Amazon the volume was intact and had been recovered successfully.
As many of you know, we have been with Amazon EC2 since the beginning of this year and this is the first significant outage we have experienced since then. Our current data partitioning and snapshotting scheme has been excellent at mitigating risk for our customers. Even today, only about 7% of all Unfuddle accounts were affected. However, we do not consider this outage to be acceptable, and in hindsight we should have probably not waited for the volume to be rebuilt, but rather restored directly from the last viable snapshot.
This morning’s events have given us some very practical ideas as to how we can even further improve upon our snapshotting strategy so that this kind of hardware failure is even less likely to affect our customers in the future. We are already working on implementing these changes.
We apologize for the disruption that this outage has caused you and your teams. As a software development team ourselves, we truly understand the kind of problems that this has caused.
-
Automated Backups with Amazon S3 Support
Since the launch of Unfuddle, we have always considered it one of our highest priorities that our customers would have direct and immediate access to their data in the form of project backups. Downloading comprehensive project backups has always been possible with Unfuddle. However, automating this process has always required writing some custom code against the Unfuddle API.
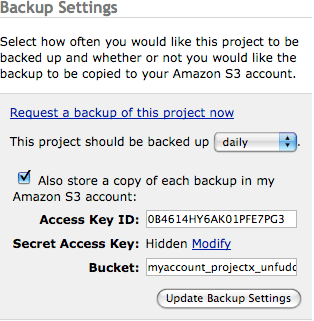 Automated Backups
Automated BackupsWe now provide the ability to schedule automatic backups of projects, removing the potential tediousness of going through the Unfuddle API. Any project or account administrator may now setup a project to be backed up daily, weekly, or monthly.
Additionally, with Unfuddle now running entirely on Amazon’s infrastructure, it seemed only natural to allow for these automated backups to be sent directly to Amazon S3 buckets. You can now specify your Amazon credentials along with an optional bucket name and all new backups will automatically be sent to your S3 account for your own storage.
-
Message Bumping and Comment Attachments
Based on comments we have received from you, our Amazon EC2 migration has been a huge success. As promised, we are ready to start rolling out enhancements to Unfuddle. Today, we are deploying the following features along with some smaller interface updates:
Message Bumping
Unfuddle messages typically function as a blog for your project. However, as message comments can often be a natural place for discussion of the message content, we have decided to move to a message sorting model similar to most forums. Now, whenever a comment is made on a message, the entire message will move to the top of the stack making the activity more obvious.
Comment Attachments
Many of you have asked for the ability to add attachments to comments. Because you asked, it is now possible to attach files to your comments throughout Unfuddle. Additionally, please note that the attachment interface has been updated throughout Unfuddle.
We are looking forward to turning more of your suggestions into enhancements to Unfuddle over the coming months!
-
Infrastructure Upgrades and Amazon EC2
 After some very long nights and a lot of very hard work, we are proud to say that Unfuddle is now running wholly on Amazon EC2 servers. Vast amounts of Unfuddle code have been completely revamped to scale horizontally and to take advantage of the Amazon approach to hosting. Site performance has improved significantly across the board with virtually infinite room to grow.
After some very long nights and a lot of very hard work, we are proud to say that Unfuddle is now running wholly on Amazon EC2 servers. Vast amounts of Unfuddle code have been completely revamped to scale horizontally and to take advantage of the Amazon approach to hosting. Site performance has improved significantly across the board with virtually infinite room to grow.Along with this infrastructure upgrade, a number of relevant software updates are now available. Most notable of these is that all Unfuddle Subversion repositories have now been upgraded to 1.5.x, bringing you new features such as Subversion merge tracking.
In choosing the Amazon platform, Unfuddle is effectively saying goodbye to Rackspace, our previous hosting provider. Rackspace was an excellent partner that served Unfuddle and its customers very well over the years. However, we simply needed to move on to an infrastructure partner that could better grow with our needs.
The Unfuddle team is very excited. Now that there is no longer an imminent need to upgrade our infrastructure, we can return to improving the feature set of Unfuddle. Many of you have been waiting patiently for more updates to Unfuddle – your comments have not gone unheard and we have some very exciting features that are now literally around the corner!